The secret step to save your software from the creeping death of unmaintainability
Abstract
Software which is developed over several years usually tends to come into a state, where the effort and risk of change increases dramatically with each new feature. This often ends at the point, where either nobody dares to take the risk of any further change, or it is simply too expensive to implement a new feature.
What is necessary to guard against this destiny and keep a software fit for change even after years of development?
Constant Change
Change is inherent to software. We software developers have overcome the mentality that you write one specification, implement it and you are done for good. History tought us that it is impossible to get all things right the first time. With the success of the agile movement the insight has manifested that software is under constant change right from the beginning. The overwhelming majority of software developers has accepted this fact as a law of nature now.
There are several sources of change. Customers change their mind over time. When using the software, they want to improve and optimize the way how the software solves their original problem. They see possibilities to increase the value the software could provide to them by adding new features. They also start to find new problems, that could also be solved with the software, maybe with some “small” modifications. Since the customer and the customer-value drive the development of a software, we have to incorporate all this into the software - somehow.
We developers also change our mind. While working on a solution for a specific problem, we learn more about this problem. Assumptions that we made in the beginning turn out to be wrong or imprecise. Algorithms that we found do not scale and need to be optimized or replaced. We do housekeeping, restructure and refactor the codebase. Especially the agile movement developed several techniques that should keep the codebase in a shape that will allow us to constantly improve and optimize its internal structures. But practice shows that it is not that easy to follow the rules over time. The one or the other shortcut will be taken from time to time.
Finally the technology that we depend on, the libraries, the underlying platforms, and the frameworks, evolve over time. New features are availabe, better alternatives are available, or a complete paradigm shift takes place.
Ten years ago, the main computing device for consumers was the PC. Broadband internet was not wide spread yet, not to mention mobile internet. If you provided an application that makes intensive use of user interaction or processes a reasonable amount of data, you would have implemented it as a desktop application for the PC. Now, post-iPhone-web-2.0, you would provide the same solution as a cloud-based service which can be used on different devices, ranging from a smartphone over the webbrowser to a rich client application on the PC.
Based on the technology available in 2006, nobody would have anticipated this. If the above mentioned software is the main asset that your business is based on, you better have a plan to adapt. Otherwise the paradigm shift may kick you out of business.
Constant Growth
Software under development is constantly growing. Each new feature is adding to the codebase, as well as each refactoring (e.g. extract method, introduce parameter object, extract class etc.) increases its size. This is not bad in itself, don’t get me wrong. For example according to the Open-Closed-Principle, one of the SOLID principles, you should implement in a way that you do not need to change existing code in order to extend its functionality. Instead you should add separate new code for the new feature and dependencies to the existing code.
Also refactoring is a necessary practice in order to keep the codebase in shape. Otherwise the “freezing” effect which makes the software inmaintainable sets in much much earlier.
So working on a codebase naturally increases its size, growth is unavoidable. But growth also causes problems. Increased complexity leads to increased costs for maintenance: there is simply more code to read and understand in order to make changes, there are more dependencies to take into account, there are more concepts, more structures to learn about.
More code usually also means more people who work on the code. This itself is a source of new complexity: the structure of teams will reflect in the codebase (Conway’s Law) and due to the increase of communication, the whole development process will become more formal and hence slow down.
Decisions
Software development, especially software architecture, is all about decisions. You need to decide about technology, algorithms, features sets, structure etc. Each decision is based on the knowledge that you have at a certain point in time and assumptions about all the things you don’t have knowledge about.
The longer a software lives, the more of the decisions will have to be revised at some point:
- you gain additional knowledge and assumptions turn out to be wrong,
- the world changes and assumptions that have been true at some point are not valid anymore.
Then the question is, how big is the effort to replace all code that is related to a certain decision? Is this even possible? If not, you will have to live with your original decision.
For each decision, you either have to implement it in a way that it can be revised later, or you have to be aware that your decision now may constraint your possibilities in the future. Since you don’t know the future alternatives, it is difficult to anticipate the consequences of this.
Responsibilities
The concept of responsibilities helps you to find related code. A responsibility can be defined as one reason for change. This means all code that has to be changed for the same reason serves the same responsibility.
According to the “Single Responsibility Principle”, responsibilities should not be mixed. Each unit of code should have only one reason to change, i.e. one responsibility.
There also exist different levels of granularity for responsibilities.
An example: the class TCPConnection allows you to send and receive data over the network using TCP.
public class TCPConnection {
public void connect() {
// ...
}
public void disconnect() {
// ...
}
public void write(char c) {
// ...
}
public char read() {
// ...
}
}
At the first glance, this class has the responsibility to handle network communication over TCP. At a closer look, it serves two separate responsibilities:
connect()anddisconnect()do connection management,write(char)andread()handle data transfer.
Over time, responsibilities tend to be mixed. For example, imagine you need to add a feature for measuring the round-trip time of the TCPConnection. It is very tempting to add just another method for this to the TCPConnection class, because everything you need is already there. This adds another responsibility to TCPConnection on the finer grained level.
Dependencies
Dependencies are obviously related to decisions. For example, you decide to use a certain graphics library. There will be code that depends on this library. You decide to use the MVC pattern, then there will be a certain structure of dependencies in your code. This structure looks different if you choose another pattern.
Dependencies are also related to responsibilites. In the TCPConnection example, there is code, that uses connect() and disconnect() to establish a connection, and there is code that uses read() and write(char) to transfer data. This code shares the dependency to the TCPConnection class, but might otherwise not be related at all.
Dependencies define the amount of impact that a certain change to the codebase has. When you modify a piece of code, then everything that depends on this piece might have to be adapted to the change. This is true for direct dependencies and might be true for indirect dependencies as well.
Dependencies tend to spread throughout the codebase over time. The more secure a decision for example for a specific technology seems to be, the higher the probability is that this technology is used directly allover the place. E.g. you decide to use SWT as your GUI library. Then all your GUI related code might directly access the SWT library. Even if you build a facade to hide SWT, the structures and constants of SWT will very likely slip through the facade and be used directly somewhere in your codebase. This makes it very difficult to revise the decision for SWT and for example replace it with JavaFX at some point.
Isolate Responsibilities and Minimize Dependencies
Let’s recap what we have until now: Software development is based on decisions that are valid only for a limited amount of time. They might have to be revised sooner or later. Responsibilities and dependencies define the amount of code that is related to a certain decision. Hence, the effort needed to revise a given decision depends on the way you care for responsibilities and dependencies in your codebase.
To keep the effort low, proper measures would be to have responsibilities isolated on a fine grained level and to minimize the number of dependencies of each unit in your codebase. There are several techniques to accomplish this. To examine those, it makes sense to first look at some code:
public void selectUserProfileImage() {
FileDialog dialog = new FileDialog(shell, SWT.OPEN);
dialog.setText("Select Image");
dialog.setFilterPath("~/images/");
dialog.setFilterExtensions({ "*.jpg", "*.png", "*.gif", "*.*" });
String selectedImageFilename = dialog.open();
if (selectedImageFilename == null) return;
Properties userSettings = new Properties();
try (BufferedReader reader = new BufferedReader(FileReader(USER_SETTINGS_FILE))) {
userSettings.load(reader)
} catch (IOException e) {
return;
}
userSettings.setProperty("profile.image.filename", selectedImageFilename);
try (FileWriter writer = new FileWriter(USER_SETTINGS_FILE)) {
userSettings.write(writer, "user settings");
} catch (IOException e) {
return;
}
updateUserProfileImageInUI();
}
The method above lets the user select an image file as her profile image. If the user actually selects one, it stores this information in the user settings and updates the UI to make sure the selected image is shown.
What are the fine-grained responsibilities that this method implements?
- handle the selection of an image file using a file dialog,
- handle the case, that the user did not select anything (by simply returning without further action),
- load the user settings from a file in the filesystem,
- handle any error condition while reading the file (by simply returning, but anyway),
- store the filename of the user profile image in the user settings,
- store the user settings into a file in the filesystem,
- handle any error condition while writing the file (by simply returning, you get it),
- make sure, that the UI is updated.
Let’s also have a look at the outgoing dependencies of the method:
- the UI framework, especially the FileDialog class,
- the underlying filesystem ("~/images/"),
- the image file formats which are supported by the application,
- the Java
Propertiesclass, - the Java IO framework.
If any decision changes which is related to one of the above responsibilities or dependencies, the method needs to be changed. And even worse, some of the responsibilities are very likely to appear also in other places in the codebase. You will have to find all places and change them all consistently - this is also called “shotgun surgery”.
Layering
A very common approach in programming is to split a problem into different layers with different levels of abstraction. The highest level provides a description on what we do, with as little technical knowledge as possible. The levels beneath take care about how we do it, with increasing technical detail as you descend the levels of abstraction. On the lowest level you find very detailed and generic implementations, that have no knowledge about the original business problem at hand.
In practice, different levels of abstraction should not be mixed in one method. Each method is on a certain level and uses methods one level below (this principle is valid for classes and packages as well).
Rewriting our top-level method using this principle would lead to something like this:
public void selectUserProfileImage() {
Optional<String> selectedImageFilename = ui.selectUserProfileImageFile();
if (selectedImageFilename.isPresent()) {
userSettings.setProfileImage(selectedImageFilename);
ui.updateUserProfileImage();
}
}
The new version describes what we do and reads pretty like the prose description I gave further above, without any technical detail on how the things are done. Many of its responsibilities were moved to other places: * all details related to the user interface and user interaction are moved into a separate object (ui) * all details related to user settings are moved into another separate object (userSettings)
Let’s have a closer look on how the file selection is further implemented:
public class UI {
// ...
public Optional<String> selectUserProfileImageFile() {
return uiFramework.selectFileToRead("Select Image", filesystem.getImagesFolder(), SUPPORTED_IMAGE_FORMATS);
}
// ...
}
public class UIFramework {
private Shell rootShell;
// ...
public Optional<String> selectFileToRead(String title, String filterPath, String[] filterExtensions) {
FileDialog dialog = new FileDialog(rootShell, SWT.OPEN);
dialog.setText(title);
dialog.setFilterPath(filterPath);
dialog.setFilterExtensions(filterExtensions);
String selectedImageFilename = dialog.open();
return Optional.ofNullable(selectedImageFilename);
}
// ...
}
The method selectUserProfileImageFile contains all the details (title, file formats, etc.) that are specific to selecting a user profile image file. On the other hand, selectFileToRead knows how to show a file dialog in order to open a file for reading. Use case specific details are separated from technical details that depend on the underlying UI framework.
Doing layering well requires discipline, because it is not easily enforced by our languages and tools out of the box. It is the developer’s responsibility to adhere to the rules which define the layers, maintain the separation of the different layers and to introduce new layers as soon as they are needed. There are in fact tools, that can help to find violations of the rules (e.g. JDepend to check dependencies), but anyway, the rules have to be defined first by the developers.
The reward of this effort is a codebase with a good separation of responsibilities and a clearer dependency structure. If you look into a certain use case, you have the choice on the level of detail you want to see. Code related to technical aspects tends to move into the lower layers and stabilizes very soon (as long as you do not change the underlying technology) while the business logic resides in the upper layers.
Business logic tends to be ugly and complex, because it takes care of all the details, shortcuts and special cases coming “real life”. Business logic is also inherently instable, because “real life” changes. Layering helps to separate this instable ugly part and keep the rest of your codebase nice and clean. Nothing should depend on ugly code.
But layering also comes with a price: the code related to one single use case is distributed in small units over several layers. If you want to understand in the very detail what is going on, you need to look at all the layers. It is easy to loose track when everything is spread over several classes, packages and modules.
Dependency Injection
Layering separates code with different levels of abstraction and helps to clarify dependencies. The next step is to loosen the coupling between different parts in your codebase. This is where dependency injection (DI) comes onto the stage. But first a little bit of code to ease the discussion with some meat:
public class UserProfileController {
private UI ui;
private UserSettings userSettings;
public UserProfileController() {
ui = new UI();
userSettings = new UserSettings();
}
public void selectUserProfileImage() {
Optional<String> selectedImageFilename = ui.selectUserProfileImageFile();
if (selectedImageFilename.isPresent()) {
userSettings.setProfileImage(selectedImageFilename);
ui.updateUserProfileImage();
}
}
}
The class UserProfileController directly depends on the classes UI and UserSettings and even worse, creates instances of those classes. Any change to one of those classes may also have impact on UserProfileController. If you want to replace one of the classes with a new implementation, this leads to a change in UserProfileController and all other places that instantiate the class.
Using dependency injection to solve this two issues, we will have to change two things: 1. UserProfileController should get the instances of UI and UserSettings from the outside (the actual injection), 2. UserProfileController should talk to interfaces instead of concrete classes.
Let’s discuss both measures in more detail:
Inject dependencies
The injection of dependencies can be implemented in three different ways: 1. injection through the constructor 2. injection through a setter 3. injection using whatever magic stemming from a decent DI framework
As usual, there are pros and cons for each variant, and you have to choose wisely in practice. Using (1) or (2), it is still easily comprehensible where the injected instances are coming from and at which point in the application life-cycle they are injected. On the other hand, this means that there is still tight coupling in the codebase between the parts where the injected classes are used and where they are instantiated. It also usually means the need to recompile the software if anything is changed in the dependency configuration.
A dependency injection framework allows much looser coupling in the whole codebase. The dependency configuration is described in a separate file or using a set of conventions. Changing the dependency structure can in the best case be done at runtime or means the need for a restart of the application in the worst case. The downside of this flexibility is, that it is less obvious what is going on in the background. There is a lot of glue provided by the framework between the units from your codebase, which makes it harder to reason about the behavior of your code. To be able to understand your application, it is mandatory to also understand the dependency injection framework to a certain degree.
Separate contract from implementation
The second step to apply dependency injection is to separate the contract from the implementation. UserProfileController should not talk directly to UI or UserSettings, but use an interface instead. This allows to easily replace either implementation, without any impact on UserProfileController. Using a setter or a DI framework, this can even happen at runtime.
Going one step further, UserProfileController should use interfaces, that contain only the part of UI and UserSettings which is needed by UserProfileController. This is also called the Interface Segregation Principle (ISP).
Dependency injections puts the wiring of objects into one dedicated place. This way it helps to reduce dependencies and coupling in your codebase. It comes with the price that sometimes it is less obvious, who the actual actors are in a certain use case.
Vertical slicing
Using a layered architecture, it is still possible to have strong coupling between the distinct features of your software. Layers just order the dependencies on the axis of abstraction. It is very easy to add dependencies within a layer or to a lower layer between parts that originally belonged to different features.
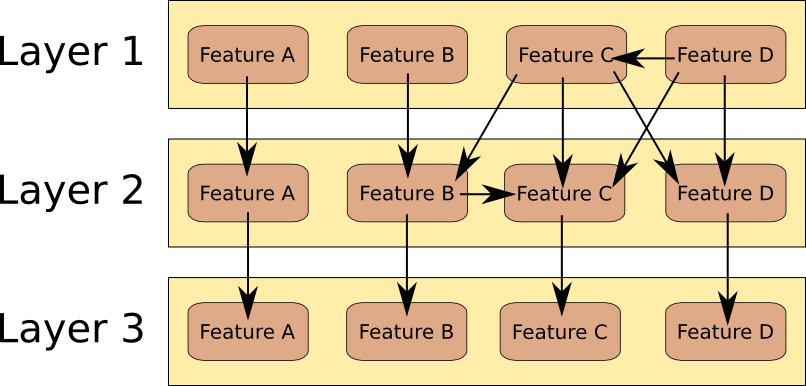
In the image above, only feature A is independent from the rest of the features. The features B-D are coupled together and may not be changed independently.
To make those dependencies explicit, you need to cut the software also into vertical slices. This makes parts in your codebase visible that, although they belong to different features, share a dependency to some common functionality. Those common parts can then be extracted, you define an interface and so on.
Another name for these vertical slices of functionality related to a certain feature with well-defined interfaces for interaction is “modules” - a very old concept in software engineering. A module has a certain responsibility and may have dependencies to other modules. With regard to layers, modules are orthogonal, i.e. a module contains all the code of a feature, regardless of the layer that the code belongs to.
While the concept of modules has, like each older concept in the software trade, undergone several re-definitions over time, there are currently several ways to use modules in practice.
In languages like Java, a very simple approach is to put everything that belongs to a certain module into one package. You can further use the concept of “package private” visibility, to distinguish the public interface of the module from its inner parts. This can all be done with bare language features, there is no need for a special module framework.
Since we are now in 2016 and some years have gone by since the discovery of modular programming, there are also more sophisticated incarnations of the module concept nowadays. Frameworks like OSGi provide much more possibilities to define and handle modules. You can have different modules that provide the same services, you can load and replace modules at runtime, modules are versioned and different versions of the same module can be present at the same time. You have control on a very fine-grained level over the public interface and the dependencies of each module. With a modern module system, you can even go so far that the actual actors of your software are determined at runtime, without the need to do any explicit wiring at development time.
All this allows you to keep different parts of your software independent of each other and keep this independence stable over time. This is key to be able to replace or remove a certain part of your codebase without too much impact on the rest. You need this ability in order to evolve features independently whenever it is needed.
The secret step to save your software from creeping death
All the things discussed so far can be called common knowledge in software engineering; I did not present any new insights until now. But all of the above techniques need to be applied scrupulously precise without any exception to be able to do the one vital step that keeps your software fit for all eventualities.
A knightmare on Wall Street
To illustrate the importance of this last step, let me tell you a story that I found on Doug Seven’s blog about a high-volume day-trading firm called Knight Capital Group.
In 2012 Knight was the largest trader in US equities with market share of around 17% on each the NYSE and NASDAQ. Knight’s Electronic Trading Group managed an average daily trading volume of more than 3.3 billion trades daily, trading over 21 billion dollars daily.
On July 31, 2012 Knight had approximately $365 million in cash and equivalents.
The NYSE decided to launch a new Retail Liquidity Program on August 1st, 2012. Hence Knight needed to adapt a part of their electronic trading software called SMARS. This update was intended to replace an 8 year old module called “Power Peg”, which was actually not used any more since years, but was still in the codebase. To activate the new SMARS module, they decided to reuse the switch witch formerly was used to activate the old “Power Peg” module.
The deployment of the software was done manually - accidentally only on 4 of 5 nodes. This meant, on one node, the old “Power Peg” code was now active. Over the years one small but vital part of the “Power Peg” module has been removed: the check which stopped the processing of an order as soon as the desired number of shares was bought or sold.
Long story short: it took the one node with the revived “Power Peg” module only 45 minutes to burn 460 million dollars (remember, they had only $365 million cash) and boost the Knight Capital Group out of business.
The Goal
Being aware of responsibilities and dependencies, separating features into modules and functionality into layers of different abstraction, applying the SOLID principles and making all this part of your daily routine; all this serves one single goal: being able to delete obsolete code when time has come.
Ok. Deleting code is hard. You have spent weeks, month, even years within certain parts of your codebase, often more time per day than with your family. These places feel comfortable, familiar, intimate. But at some point in time, reality changes, and you will come to the conclusion that the concepts you are using do not work anymore in the changed reality. Whatever you try, you are not able to bend the new reality around your old concepts.
This is the point where it is time to say goodbye. You need to replace the code with a new implementation. And replacing here means: delete the old code, add a new implementation. The good news are: when your codebase is in good shape and all the affected parts are already separated, odds are good that you can keep a much bigger amount of your beloved code.
Deleting obsolete code reduces the size of your codebase and lowers the impact of the constant growth. Less code always means less bugs. Deleting obsolete code also eliminates the possibility that old code is accidentally revived and bites you in the back when you least expect it.
So the secret to save your software from the creeping death of inmaintainability is easy:
- Be aware of responsibilities and dependencies,
- whenever you make a decision, also think about how to revert it,
- keep separate things separate,
- DELETE OBSOLETE CODE.
References
- Write code that is easy to delete, not easy to extend, @tef
- The wrong abstraction, Sandi Metz
- The Burden of Features in Software, Jan van Ryswyck
- Principles of OOD, Robert C. Martin
- The Open Closed Principle, Robert C. Martin
- The Single Responsibility Principle, Robert C. Martin
- Conway’s Law, Melvin E. Conway
- Shotgun surgery
- Fundamental Theorem of Software Engineering
- Knightmare, Doug Seven
- SEC filing on Knight Capital Group
- On the Criteria To Be Used in Decomposing Systems into Modules, D. L. Parnas